Labelling Cans on a Production Line
Automating Metadata Creation
Jo Cook, Astun Technology
Debora Cartagena Pixnio, CC-0
Metadata is important, but in large organisations data discovery, metadata creation, and management can be expensive and time-consuming
Pigsels, CC-0
Metadata is also complex, and often data owners have neither the time or the training to complete records in a traditional catalog, or to keep them up to date
Michael Jastremski, openphoto.net
Luckily we can automate much of the discovery and metadata creation processes
One open source option for this is the Metadata Crawler plugin for Talend Open Studio (aka Crawler)
Sam Storino
Crawler looks for spatial data in file systems and databases. For each data source it finds, it derives as much of the metadata as it can
wikimedia.org CC-BY-3.0
Crawler creates a metadata record for each data source it discovers, and a Feature Catalog record for vector data sources.
It can insert these records into any Metadata Catalog with a CSW-T (Transactional CSW) endpoint.
For UK metadata, we've modified Crawler so that it outputs metadata in Gemini 2.3 format (and ISO19110 for the Feature Catalog)
Flickr: Eric Danley CC-BY-2.0

At this stage in proceedings, we have a record for each data source, with some programmatic elements, some placeholder elements, and a linked feature catalog record describing the attributes. Human hands have yet to touch the metadata!
IMGUR: goldenretrieverbailey
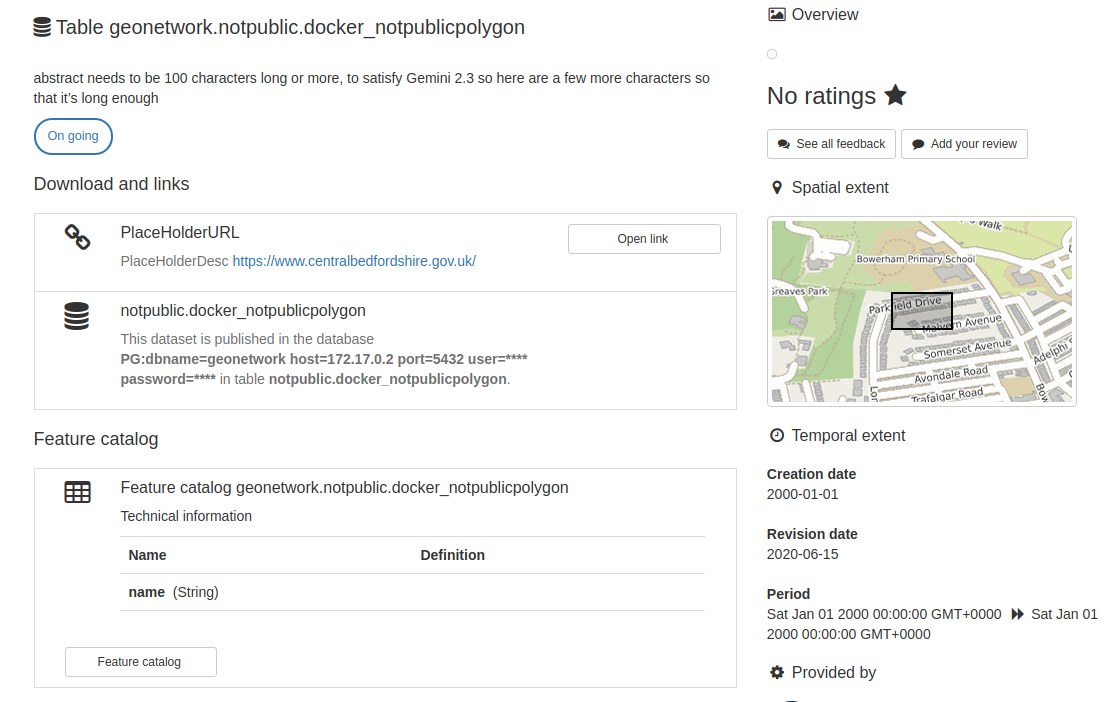
We generate excel spreadsheets with a row per record for data owners to complete the manual fields.
This may seem clumsy but excel is well-known and used. Data owners can copy and paste in bulk to populate "their" records quickly and easily.
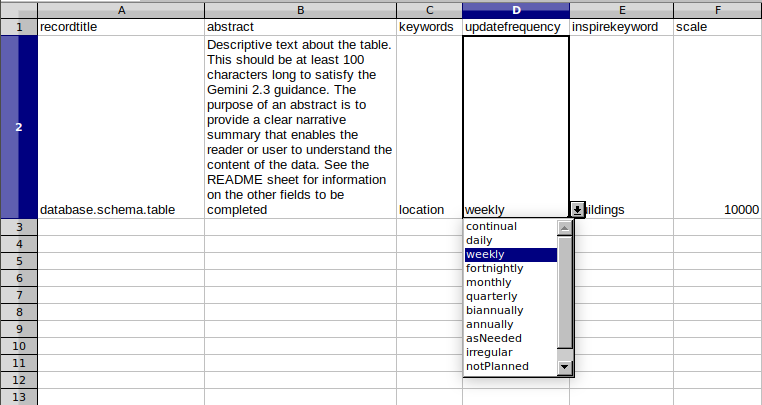
We can then use the GeoNetwork API inside a python script to iterate through the csv and update the metadata in the catalog with the unique values
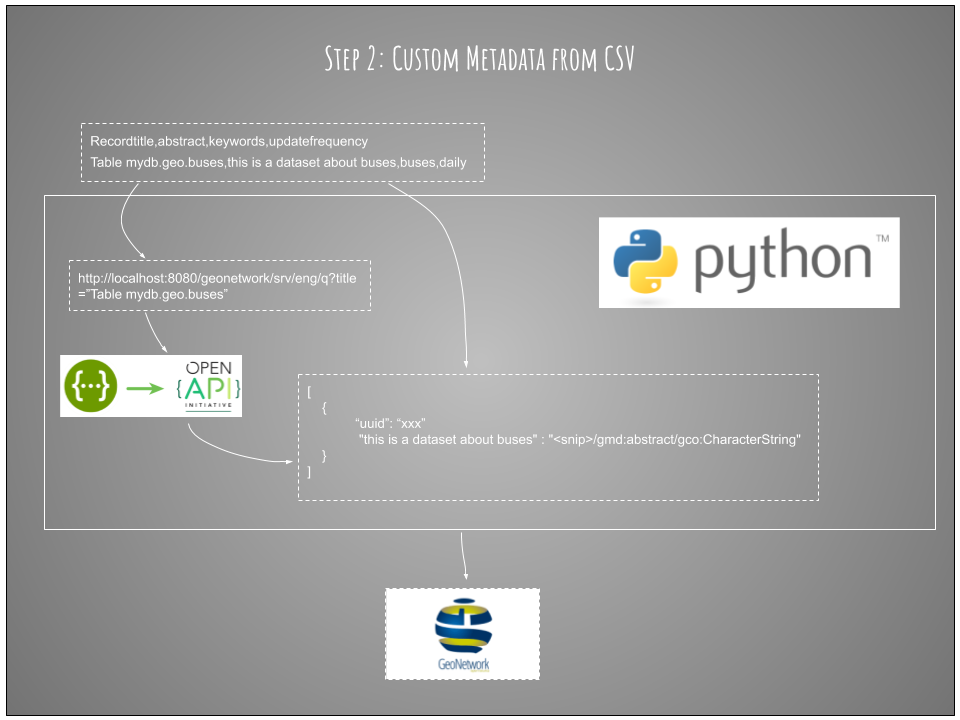
For extra geek points, and to automate the workflow even more, we can allow people to send the spreadsheet as a csv to an email address associated with an S3 bucket
With another bit of python we can extract and validate the csv, then ensure it's ready for the previous script to process
Using the Talend gui you can configure Crawler to enable/disable parts of the workflow
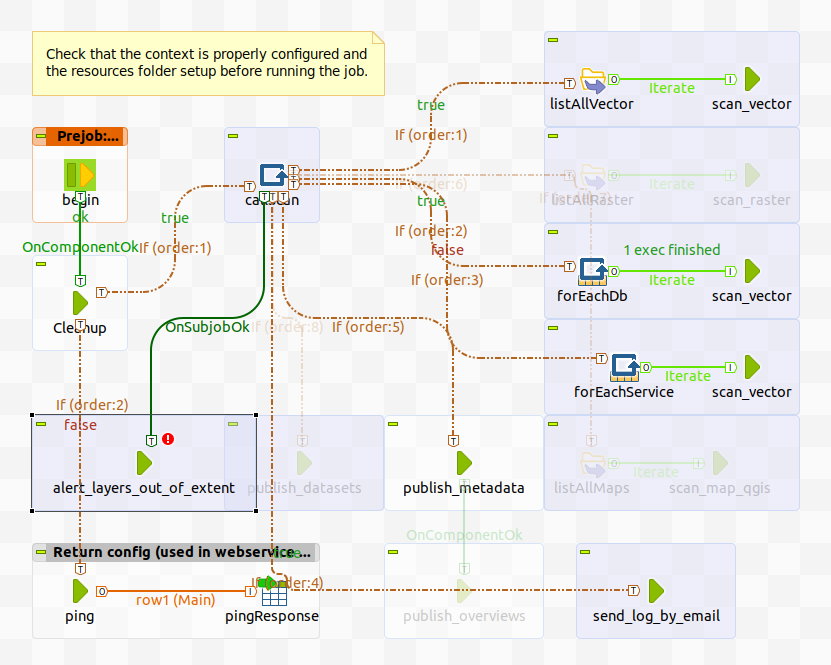
You can also configure the database, file location, metadata catalog and so on:
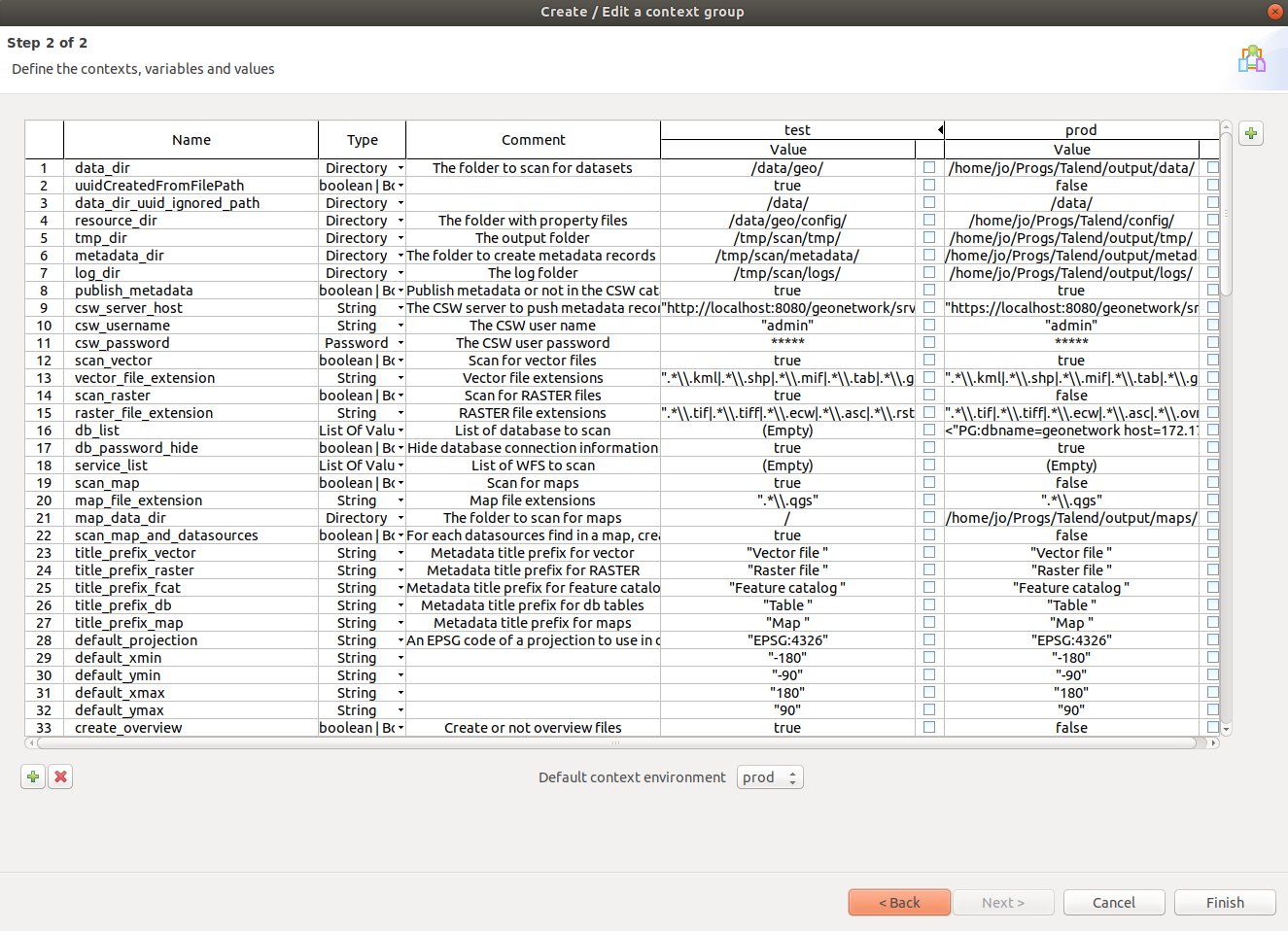
Then Crawler can be exported as a batch file for windows or a shell script for linux, to run as an unattended scheduled task
You can override the config at the command line, for example to crawl a different database or use a different metadata catalog
Demo Alert (If time allows)!
Flickr: Bernard Duport CC-BY-SA-2.0
Zero to Hero:
With some initial setup and configuration we get a system that automatically discovers data sources and creates metadata, and allows data owners to keep them up to date by sending spreadsheets via email with little time-consuming management and editing
US Airforce
Where to find the components
www.talend.com/products/talend-open-studio/talend-spatial.github.io/
github.com/talend-spatial/workspace-metadata-crawler
Thank You!
Jo Cook, Astun Technology

Labelling Cans on a Production Line